筑業吉林資料升級 推動吉林地標建設——解析《建筑工程資料管理標準 DB22/JT 127-2014》及其工程管理服務

隨著建筑行業的快速發展,建筑工程資料管理日益成為確保工程質量和進度的重要環節。筑業吉林作為專業的工程管理服務提供商,近期對其資料系統進行了全面升級,以更好地適應吉林省建筑地標項目的需求,并嚴格遵循《建筑工程資料管理標準 DB22/JT 127-2014》(簡稱DB22/JT 127-2014)。本文將探討這一升級的意義,并深入解析該標準的核心內容及其對工程管理服務的積極影響。
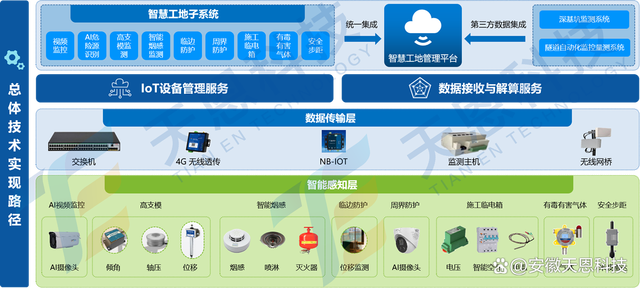
筑業吉林的資料升級旨在提升工程資料數字化水平,通過集成先進的信息技術,實現從項目立項到竣工驗收的全過程資料管理。這不僅提高了數據準確性,還加快了信息流轉速度,為吉林的地標建筑工程提供了強有力的支持。例如,在高層建筑和大型公共設施項目中,標準化的資料管理有助于減少人為錯誤,確保建設過程符合監管部門的要求。
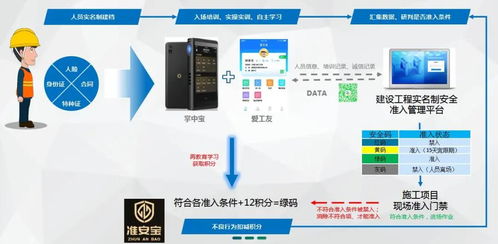
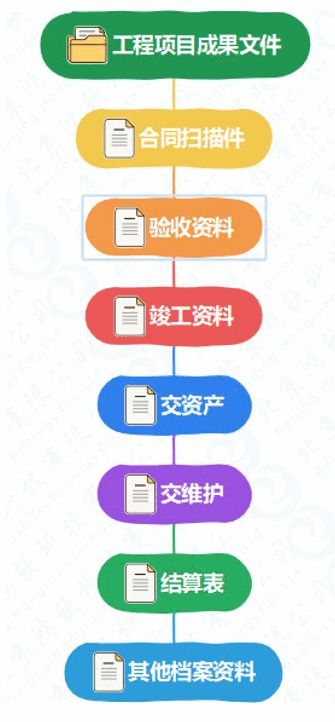
《建筑工程資料管理標準 DB22/JT 127-2014》是吉林省地方標準,專門針對建筑工程資料的分類、編制、歸檔和移交等方面制定了詳細規范。該標準強調資料的真實性、完整性和及時性,要求工程各方在施工過程中嚴格執行。例如,標準明確了施工日志、材料檢驗報告和安全記錄等關鍵文檔的格式要求,幫助施工單位規避潛在風險。筑業吉林的升級系統正是基于此標準進行優化,確保資料管理與吉林省政策無縫對接。
在工程管理服務方面,筑業吉林提供全方位的支持,包括資料審核、培訓和咨詢服務。通過采用DB22/JT 127-2014標準,他們能夠幫助客戶提高項目效率,降低合規成本。實際應用中,例如在長春某商業綜合體項目中,筑業吉林的資料管理系統協助團隊快速生成標準報告,縮短了審批時間,提升了整體工程質量。
筑業吉林的資料升級與《建筑工程資料管理標準 DB22/JT 127-2014》的結合,為吉林省的建筑行業注入了新動力。這不僅推動了地標項目的順利實施,還為工程管理服務樹立了標桿。隨著技術的進一步發展,這種標準化和數字化管理將更廣泛地應用于各類工程中,助力建筑行業持續升級。
如若轉載,請注明出處:http://www.writehome.cn/product/44.html
更新時間:2026-06-19 12:17:19